
안녕하세요. NOX입니다. Queue 컬렉션에 이어서 Set 컬렉션에 대해 알아보겠습니다.
[Java]Collection(3) - Queue, Deque
안녕하세요. List 컬렉션에 이어 Queue 컬렉션에 대해 알아보겠습니다. [Java] Collection(2) - List안녕하세요. 이번 포스팅은 자바 컬렉션의 리스트에 대해서 작성해보겠습니다.그전에 작성했던 포스
lumos-maxima-nox.tistory.com
Set Collection
`Set Collection` 의 특징으로는 다음과 같습니다.
- 저장된 요소는 순서가 없음
- 중복 저장을 허용하지 않음
동일한 구슬은 두개 이상 넣을 수 없고 들어갈 때와 나올 때가 다른 구슬주머니에 비유할 수 있습니다.
Set 인터페이스를 구현한 클래스들은 다음과 같습니다.
- HashSet
- LinkedSet
- TreeSet
Set Collection 의 주요 메서드
| 기능 | 메소드 | 설명 |
| 객체 추가 | boolean add(E e) | 주어진 객체를 성공적으로 저장하면 true 리턴, 중복 객체면 false 리턴 |
| 객체 검색 | boolean contains(Object o) | 주어진 객체가 저장되어 있는지 여부 |
| isEmpty() | 컬렉션이 비어 있는지 조사 | |
| Iterator<E> iterator() | 저장된 객체를 한 번씩 가져오는 반복자 리턴 | |
| int size() | 저장되어 있는 전체 객체 수를 리턴 | |
| 객체 삭제 | void clear() | 저장된 모든 객체를 삭제 |
| boolean remove(Object o) | 주어진 객체를 삭제 |
`List Collection`과 달리 인덱스로 객체를 검색하여 가져오는 메서드가 없어 `for문` 또는 `iterator()` 반복자를 사용하여 요소들을 가져옵니다.
iterator 메서드
| 리턴타입 | 메서드 | 설명 |
| boolean | hasNext() | 가져올 객체가 있으면 true를 리턴하고 없으면 false를 리턴한다. |
| E | next() | 컬렉션에서 하나의 객체를 가져온다 |
| void | remove() | next()로 가져온 객체를 Set컬렉션에서 제거한다. |
HashSet
먼저 `HashSet` 부터 알아보겠습니다.
`Set Collection`의 특징과 같이 저장된 데이터에 순서가 없고, 중복 저장이 되지 않습니다.
`HashSet` 은 데이터 중복 방지를 위하여 `Hashtable`구조를 이용한 `HashMap`을 이용하여 만들어졌습니다.
`Map`의 특성 중 하나인 '중복 Key는 존재할 수 없다'는 특징을 이용하여, Key는 `Set`의 값으로, `Value`에는 더미 객체를 저장하는 방식으로 객체를 추가합니다.
{kind=link}
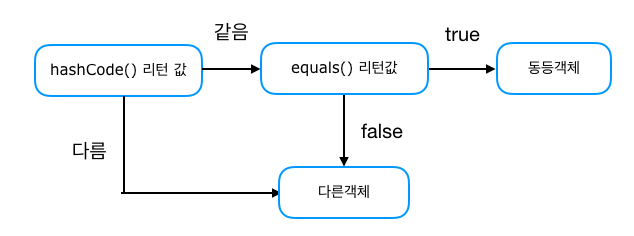
중복 방지를 위하여 아래의 그림과 같은 과정을 거치게 됩니다.
데이터 저장 시 기존 데이터와 `hashCode()`의 리턴값이 같고, `equals()`의 반환값이 `true`이면 동일 객체라고 판단하여 저장하지 않는 방식으로 중복 데이터를 방지합니다.

`HashSet`은 `null` 값을 허용하지만 중복 방지의 이유로 하나의 `null` 값만 저장할 수 있습니다.
시간 복잡도
- 검색/삽입/삭제 : O(1)
- 해시 충돌 시 삽입 최악 시간 복잡도 : O(n)
💡 Big O 시간복잡도
-> 알고리즘의 성능을 나타내는 표기법
성능이 좋은 순서대로 O(1) - O(log N) - O(N) - O(NlogN) - O(n²) - O(n³) - O(2ⁿ)입니다
💡 해시충돌(Hahs Collision)?
해시 충돌은 서로 다른 데이터가 동일한 해시 코드를 반환할 때 발생합니다. HashSet에서 해시 충돌이 발생하면, 충돌이 일어난 해시 버킷에 새로운 노드를 연결하여 데이터들을 연결 리스트 형태로 관리합니다. 이를 체이닝(Chaining) 방식이라고 하며, 충돌이 발생할 때마다 연결 리스트의 끝에 차례로 추가됩니다. 따라서, 체이닝의 방식의 최악 시간 복잡도가 O(n) 이 되며, 이는 모든 요소가 하나의 해시 버킷에 연결될 경우 발생합니다.
자바 8 이후로는 연결 리스트가 길어지면 트리(Tree) 구조로 변환하여 성능을 최적화합니다.
TreeSet
`TreeSet`은 검색기능을 강화시킨 `Set`입니다.
레드블랙트리 기반의 이진트리 자료구조를 이용하여 정렬된 `Set` 컬렉션을 제공합니다.
데이터가 오름차순으로 정렬된 상태로 저장하게 됩니다. 사용자 정의 정렬도 가능한데, `Comparable` 인터페이스를 구현하고 있어야 가능합니다.
💡Comparable?
TreeSet에 저장되는 객체와 TreeMap에 저장되는 키 객체는 저장과 동시에 오름차순으로 정렬되는데, Comparable 인터페이스를 구현하고 있어야 정렬이 가능합니다.
Comparable 인터페이스에는 CompareTo() 메서드가 정의되어 있으며, 사용자 정의 정렬을 하고 싶다면 이 메서드를 재정의해서 객체 비교 결과를 리턴해야 합니다.
TreeSet 메서드
| 리턴타입 | 메서드 | 설명 |
| E | fisrt() | 제일 낮은 객체를 리턴 |
| E | last() | 제일 높은 객체를 리턴 |
| E | lower(E e) | 주어진 객체보다 바로 아래 객체를 리턴 |
| E | higher(E e) | 주어진객체보다 바로 위 객체를 리턴 |
| E | floor(E e) | 주어진 객체와 동등한 객체가 있으면 리턴, 만약 없다면 주어진 객체의 바로 아래의 객체를 리턴 (내림) |
| E | celling(E e) | 주어진 객체와 동등한 객체가 있으면 리턴, 만약 없다면 주어진 객체의 바로 위의 객체를 리턴(올림) |
| E | pollFirst() | 제일 낮은 객체를 꺼내오고 컬렉션에서 제거함 |
| E | pollLast() | 제일 높은 객체를 꺼내오고 컬렉션에서 제거함 |
| Iterator | descendingIteratior() | 내림차순으로 정렬된 iterator를 리턴 |
| NavigableSet<E> | descendingSet() | 내림차순으로 정렬된 NavigableSet을 리턴 |
| NavigableSet<E> | headSet( E toElement, boolean inclusive ) |
주어진 객체보다 낮은 객체들을 NavigableSet으로 리턴, 주어진 객체 포함 여부는 두 번째 매개값에 따라 달라짐 |
| NavigableSet<E> | tailSet( E fromElement, boolean inclusive ) |
주어진 객체보다 높은 객체들을 NavigableSet으로 리턴. 주어진 객체 포함 여부는 두 번째 매개값에 따라 달라짐 |
| NavigableSet<E> | subSet( E fromElement, boolean fromInclusive, E toElement, boolean tolnclusive ) |
시작과 끝으로 주어진 객체 사이의 객체들을 NavigableSet으로 리턴. 시작과 끝 객체의 포함 여부는 두번째, 네번째 매개값에 따라 달라짐 |
시간 복잡도
- 검색/삽입/삭제 : O(logN)
💡 Big O 시간복잡도
-> 알고리즘의 성능을 나타내는 표기법
성능이 좋은 순서대로 O(1) - O(log N) - O(N) - O(NlogN) - O(n²) - O(n³) - O(2ⁿ)입니다
LinkedHashSet
`LinkedHashSet`은 순서가 있는 `HashSet`입니다.
이중 연결 리스트와 `HashSet`이 결합되어 삽입 순서대로 요소를 반복할 수 있습니다.
`HashSet`과 마찬가지로 중복 저장은 안 되며 `null`값을 하나 허용합니다.
`LinkedHashSet`은 `HashSet`을 상속받아 구현되나, `LinkedHashMap`을 이용하여 `LinkedHashMap`의 특징을 그대로 계승합니다.
LinkedHashSet 예제
import java.util.LinkedHashSet;
public class LinkedHashSetExample {
public static void main(String[] args) {
// LinkedHashSet 생성
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
// 요소 추가
linkedHashSet.add("Apple");
linkedHashSet.add("Banana");
linkedHashSet.add("Cherry");
linkedHashSet.add("Date");
linkedHashSet.add("Banana"); // 중복 추가 (무시됨)
System.out.println("LinkedHashSet의 모든 요소: " + linkedHashSet); //[Apple, Banana, Cherry, Date] 순서대로 들어감
// 요소 제거
linkedHashSet.remove("Cherry");
System.out.println("Cherry 제거 후: " + linkedHashSet); //[Apple, Banana, Date] 순서 유지
// 특정 요소가 존재하는지 확인
boolean hasApple = linkedHashSet.contains("Apple");
System.out.println("Apple이 존재하는가? " + hasApple); //true 반환
}
}
시간 복잡도
- 검색/삽입/삭제 : O(1)
- 해시 충돌 시 삽입 최악 시간복잡도 : O(n)
💡 Big O 시간복잡도
-> 알고리즘의 성능을 나타내는 표기법
성능이 좋은 순서대로 O(1) - O(log N) - O(N) - O(NlogN) - O(n²) - O(n³) - O(2ⁿ)입니다
이렇게 Set Collection에 대해 알아보았습니다.
도움이 되셨다면 공감 한 번 부탁드리며 잘못된 정보가 있다면 언제든 댓글 달아주세요!🪄
⬇️ 참고 URL
https://www.codelatte.io/courses/java_programming_basic/51BDPYQYSJVHNR4R
https://tecoble.techcourse.co.kr/post/2020-07-29-equals-and-hashCode/
책 '이것이 자바다'
'프로그래밍언어 > Java' 카테고리의 다른 글
| [Java]Collection(5) -Map (5) | 2024.11.07 |
|---|---|
| [Java]Collection(3) - Queue, Deque (0) | 2024.11.05 |
| [Java] Collection(2) - List (2) | 2024.11.04 |
| [Java] Collection(1) - 컬렉션 프레임워크 (0) | 2024.11.01 |